01 · Async capture
Log every call. Slow zero of them.
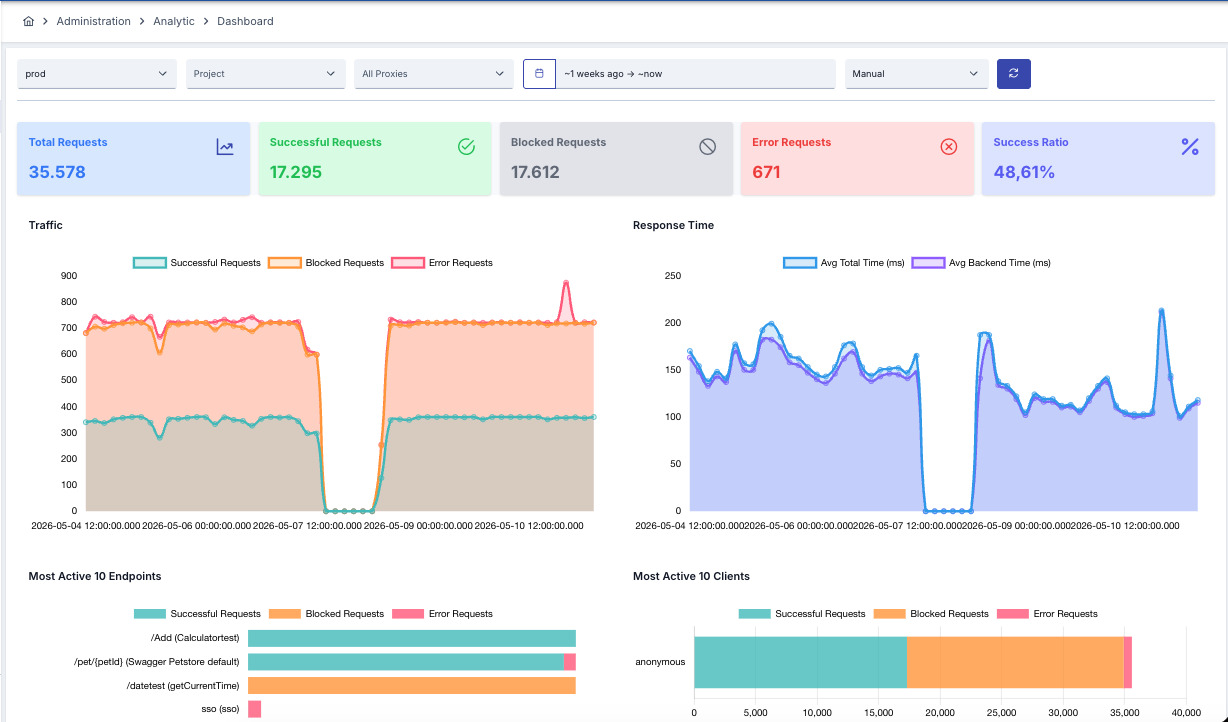
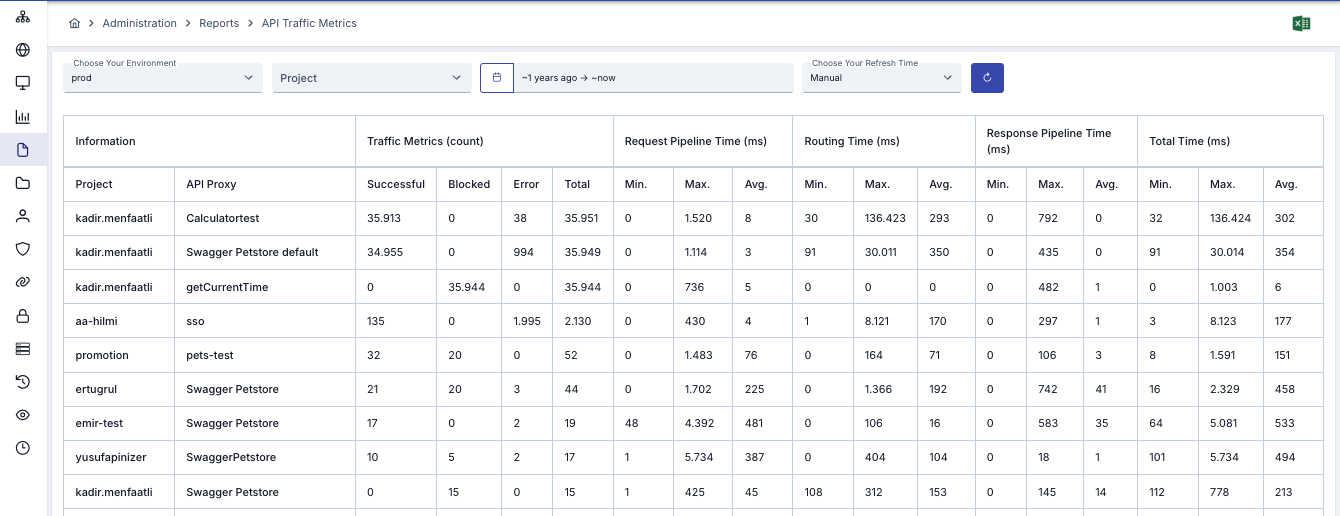
Traffic capture happens off the request lifecycle. The gateway hands the log record to a non-blocking pipeline and keeps serving — clients see the response while the pipeline is still batching, hashing, and shipping. No log shipper sidecar to keep alive, no buffer to overflow, no latency tax for visibility.
- Capture runs off the hot path — zero added latency on the request
- Non-blocking, back-pressured queue between the worker and the destinations
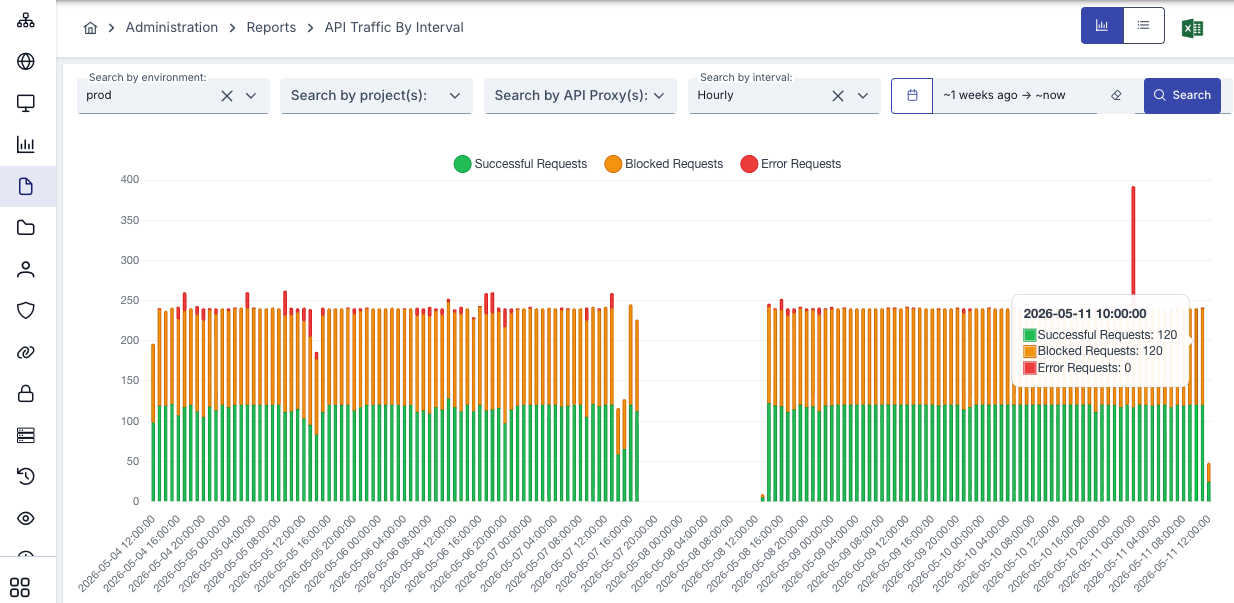
- Batches buffered in memory, shipped on a separate lane
- Worker pods stay focused on routing and policy execution
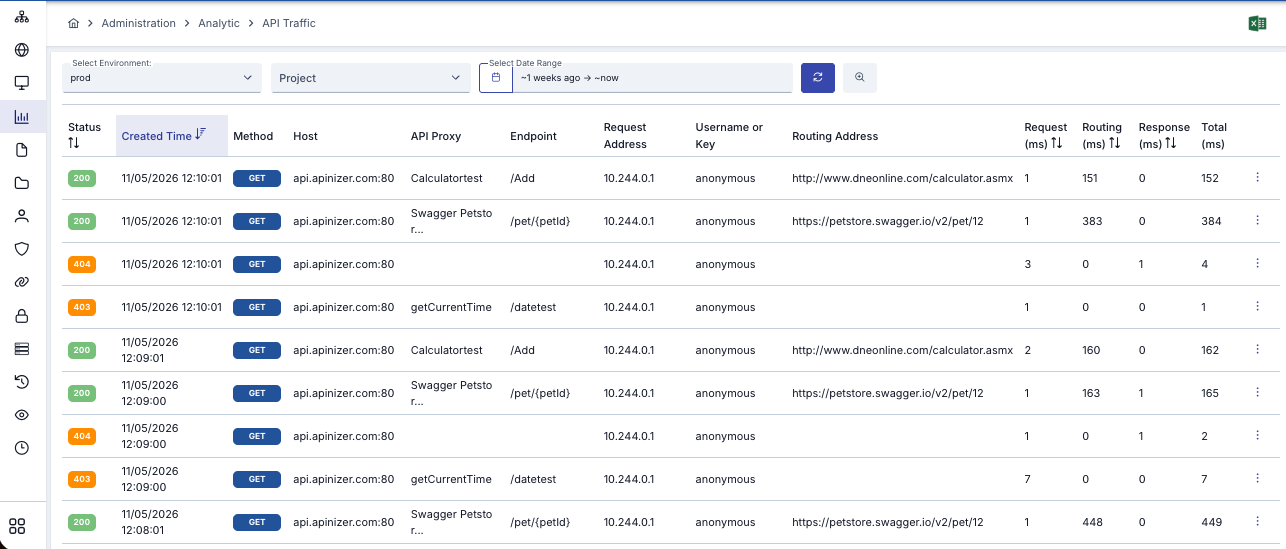
- Same capture covers REST, SOAP, gRPC, AI Gateway, and agent-to-agent traffic
- Built on virtual threads — high-concurrency safe out of the box
- Failover destination catches anything a primary connector misses
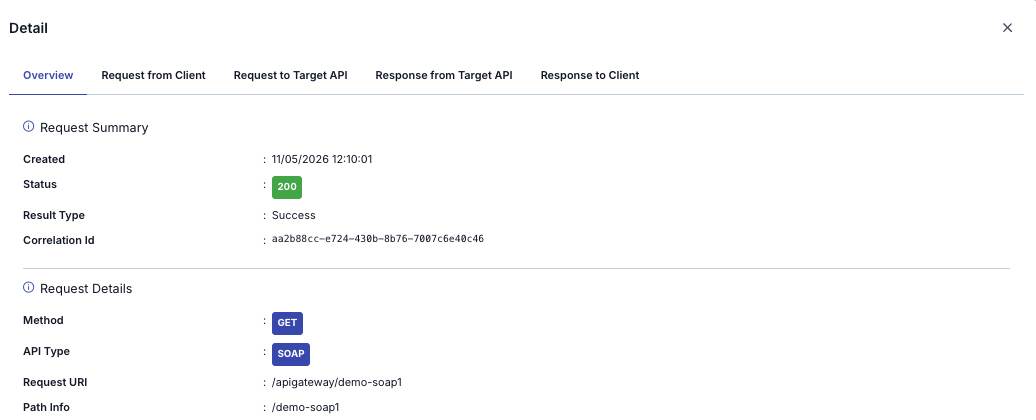
- Privacy and masking applied before the record leaves the pod
- Off the hot path
- Non-blocking
- Batched
- Failover
- REST · AI · A2A